Microbial Growth rates in R#
There are various ways to estimate microbial population growth rates from different types of abundance data. Here we will take a look at some different approaches, from applying linear models to the exponential phase, through to fitting non-linear models to the full growth curve.
We’re going to use various r packages: ggplot for nice figures, minpack.lm for levenberg marquardt nls fitting, zoo and dplyr for useful functions to perform a rolling regression (you’ll see later), and finally nls.multstart for an alternative to estimating nls starting parameters.
Learning goals#
Fit microbial growth curves using linear and nonlinear approaches
Estimate key growth parameters (lag, maximum growth rate, carrying capacity)
Compare alternative growth models using AIC and diagnostics
Compute and interpret doubling times from fitted models
Prerequisites#
The NLLS chapter and comfort fitting models in R
R packages used in the notebook installed (e.g. ggplot2, minpack.lm, dplyr)
# If you run this locally and get "there is no package called ...":
# install.packages(c("ggplot2", "minpack.lm", "zoo", "dplyr", "nls.multstart"))
library("ggplot2")
library("minpack.lm")
library("zoo")
library("dplyr")
library("nls.multstart")
First off, lets make an example dataset of microbial popultion growth by cell counts which produces a plausible looking sigmoidal growth curve
t <- seq(0, 22, 2)
N <- c(32500, 33000, 38000, 105000, 445000, 1430000, 3020000, 4720000, 5670000, 5870000, 5930000, 5940000)
set.seed(1234) # set seed to ensure you always get the same random sequence
data <- data.frame(Time = t, N = N + rnorm(length(t), sd = 0.1)) # add some random error
head(data)
| Time | N | |
|---|---|---|
| <dbl> | <dbl> | |
| 1 | 0 | 32499.88 |
| 2 | 2 | 33000.03 |
| 3 | 4 | 38000.11 |
| 4 | 6 | 104999.77 |
| 5 | 8 | 445000.04 |
| 6 | 10 | 1430000.05 |
Now let’s plot these “data”:
ggplot(data, aes(x = Time, y = N)) +
geom_point(size = 3) +
labs(x = "Time (Hours)", y = "Population size (cells)") +
theme_bw(base_size = 16)
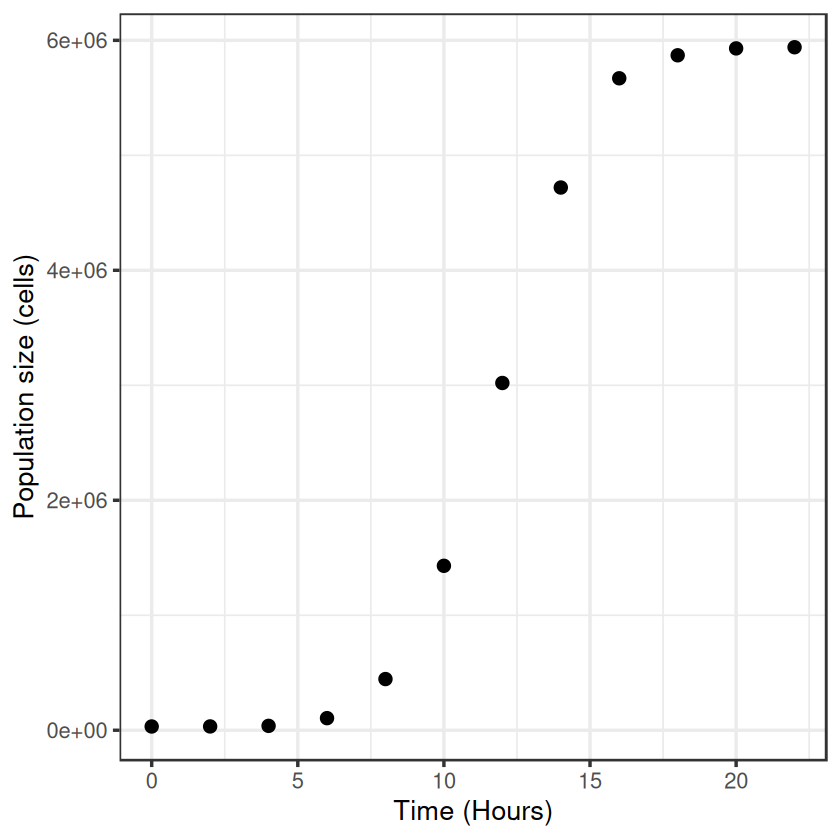
Basic linear approaches#
OK, so how do we calculate the growth rate from these data?
The size of an exponentially growing population (\(N\)) at any given time (\(t\)) is given by:
\( N(t) = N_0 \cdot e^{rt} , \)
where \(N_0\) is the initial population size and \(r\) is the growth rate. We can re-arrange this to give:
\( r = \frac{\log(N(t)) - \log(N_0)}{t} , \)
i.e. in exponential growth at a constant rate, the growth rate can be simply calculated as the difference in the log of two population sizes, over time. We will log-transform the data and estimate by eye where growth looks to be exponential.
data$LogN <- log(data$N)
data$Log10N <- log10(data$N) # for later
# visualise
ggplot(data, aes(x = Time, y = LogN)) +
geom_point(size = 3) +
labs(x = "Time (Hours)", y = "log(cell number)") +
theme_bw(base_size = 16)
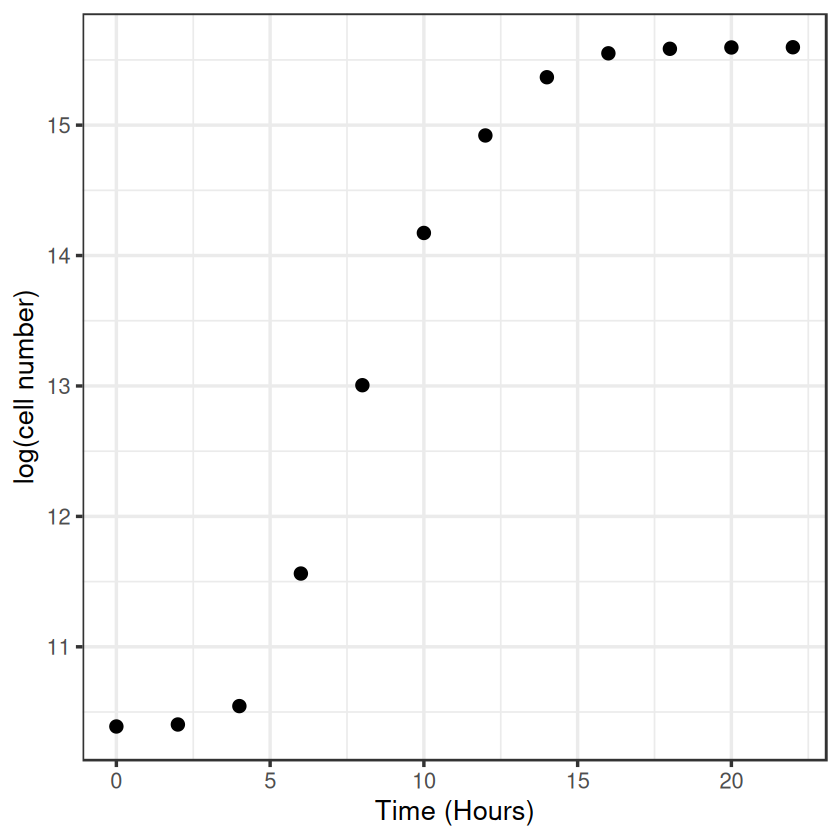
By eye the logged data looks fairly linear between hours 4 and 10, so we’ll use that time-period to calculate the growth rate.
(data[data$Time == 10,]$LogN - data[data$Time == 4,]$LogN)/(10-4)
So our first, most basic estimate of \(r\) is around 0.6.
But we can do better than this. To account for some error in measurement, we shouldn’t really take the data points directly, but fit a linear model through them instead, where the slope gives our growth rate. This is pretty much the “traditional” way to calculate microbial growth rates - draw a straight line through the linear part on log-transformed data.
lm_growth <- lm(LogN ~ Time, data = data[data$Time > 2 & data$Time < 12,])
summary(lm_growth)
Call:
lm(formula = LogN ~ Time, data = data[data$Time > 2 & data$Time <
12, ])
Residuals:
3 4 5 6
0.072972 -0.143423 0.067930 0.002521
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.00684 0.20297 39.45 0.000642 ***
Time 0.61638 0.02762 22.32 0.002002 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1235 on 2 degrees of freedom
Multiple R-squared: 0.996, Adjusted R-squared: 0.994
F-statistic: 498 on 1 and 2 DF, p-value: 0.002002
About the same \(r \approx 0.62\).
But this is still not great, we only estimated the exponential phase by eye, we could do it better by iterating through different windows of points, comparing the slopes and finding which the highest is to give the maximum growth rate, \(r_{max}\). This is called a rolling regression.
rolling regression#
I’m going to borrow the code from one of Dan Padfield’s github posts to do it: https://padpadpadpad.github.io/post/calculating-microbial-growth-rates-from-od-using-rolling-regression/ This requires zoo::rollapplyr() and dplyr::do()
# create the rolling regression function
roll_regress <- function(x){
temp <- data.frame(x)
mod <- lm(temp)
temp <- data.frame(slope = coef(mod)[[2]],
slope_lwr = confint(mod)[2, ][[1]],
slope_upr = confint(mod)[2, ][[2]],
intercept = coef(mod)[[1]],
rsq = summary(mod)$r.squared, stringsAsFactors = FALSE)
return(temp)
}
# define window - here every ~8 hours (window of 4 points)
num_points <- 4
# run rolling regression on LogN ~ Time
models <- data %>%
do(cbind(model = select(., LogN, Time) %>%
zoo::rollapplyr(width = num_points, roll_regress, by.column = FALSE, fill = NA, align = 'center'),
time = select(., Time),
ln_od = select(., LogN))) %>%
rename_all(., gsub, pattern = 'model.', replacement = '')
# create predictions
preds <- models %>%
filter(., !is.na(slope)) %>%
group_by(Time) %>%
do(data.frame(time2 = c(.$Time - 2, .$Time + 4))) %>%
left_join(., models) %>%
mutate(pred = (slope*time2) + intercept)
growth_rate <- filter(models, slope == max(slope, na.rm = TRUE))
# plot rolling regression
ggplot(data, aes(Time, LogN)) +
geom_point(size = 3) +
geom_line(data = preds, aes(x = time2, y = pred, group = Time), col = 'red', alpha = 0.5) +
theme_bw(base_size = 16) +
annotate(geom = 'text', x = 1, y = 15, label = paste('r_max = ', round(growth_rate$slope, 2), ' hr-1\n95%CI:(',round(growth_rate$slope_lwr, 2), '-', round(growth_rate$slope_upr, 2), ')', sep = ''), hjust = 0) +
labs(x = "Time (hours)",
y = "log(cell number)")
Joining with `by = join_by(Time)`
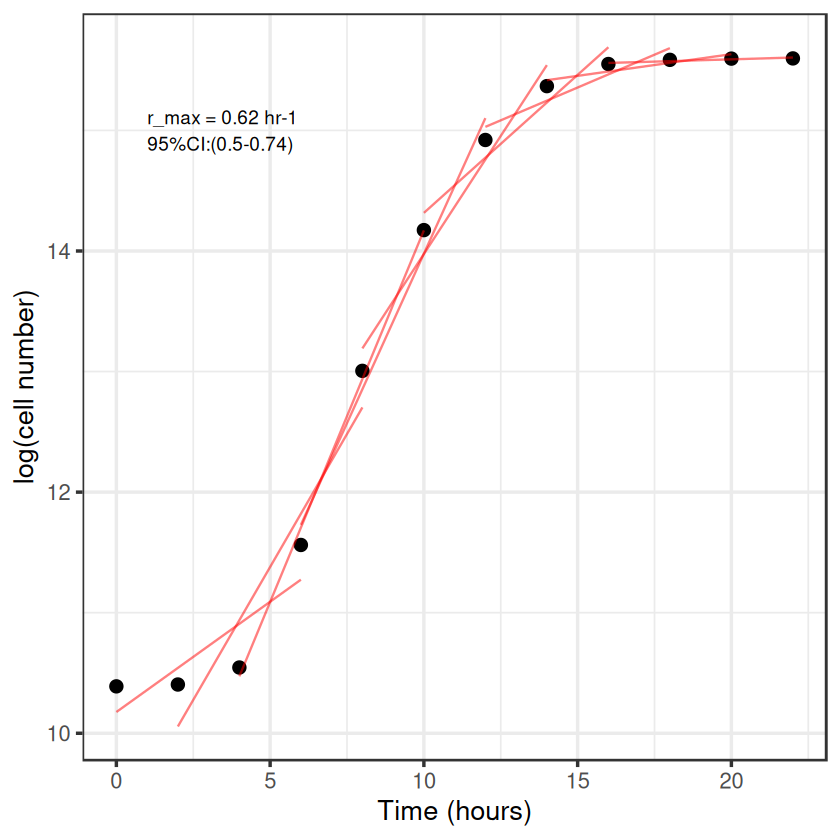
There we go, same answer as before, but we’ve done it iteratively to find the highest slope rather than estimate it by eye.
This is fine, but probably quite computationally intensive were we trying to do this for a large dataset of different growth curves. It would be better to just fit a single model to the full curve and pull out the growth rate that way.
nls model fitting#
One seemingly useful model would be the logistic growth equation where the growth rate slows as the population size nears carrying capacity (usually given as \(K\) in the ecological literature, but here we’ll use \(N_{max}\)).
logistic_model <- function(t, r_max, N_max, N_0){ # The classic logistic equation
return(N_0 * N_max * exp(r_max * t)/(N_max + N_0 * (exp(r_max * t) - 1)))
}
# first we need some starting parameters for the model
N_0_start <- min(data$N) # lowest population size
N_max_start <- max(data$N) # highest population size
r_max_start <- 0.62 # use our linear estimate from before
fit_logistic <- nlsLM(N ~ logistic_model(t = Time, r_max, N_max, N_0), data,
list(r_max=r_max_start, N_0 = N_0_start, N_max = N_max_start))
summary(fit_logistic)
Formula: N ~ logistic_model(t = Time, r_max, N_max, N_0)
Parameters:
Estimate Std. Error t value Pr(>|t|)
r_max 6.379e-01 1.444e-02 44.186 7.78e-12 ***
N_0 2.993e+03 5.051e+02 5.925 0.000222 ***
N_max 5.988e+06 2.935e+04 204.044 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 48220 on 9 degrees of freedom
Number of iterations to convergence: 11
Achieved convergence tolerance: 1.49e-08
# plot it:
timepoints <- seq(0, 22, 0.1)
logistic_points <- logistic_model(t = timepoints, r_max = coef(fit_logistic)["r_max"], N_max = coef(fit_logistic)["N_max"], N_0 = coef(fit_logistic)["N_0"])
df1 <- data.frame(timepoints, logistic_points)
df1$model <- "Logistic"
names(df1) <- c("Time", "N", "model")
ggplot(data, aes(x = Time, y = N)) +
geom_point(size = 3) +
geom_line(data = df1, aes(x = Time, y = N, col = model), size = 1) +
theme_bw(base_size = 16) + # make the background white
theme(aspect.ratio=1)+ # make the plot square
labs(x = "Time", y = "Cell number")
Warning message:
“Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.”
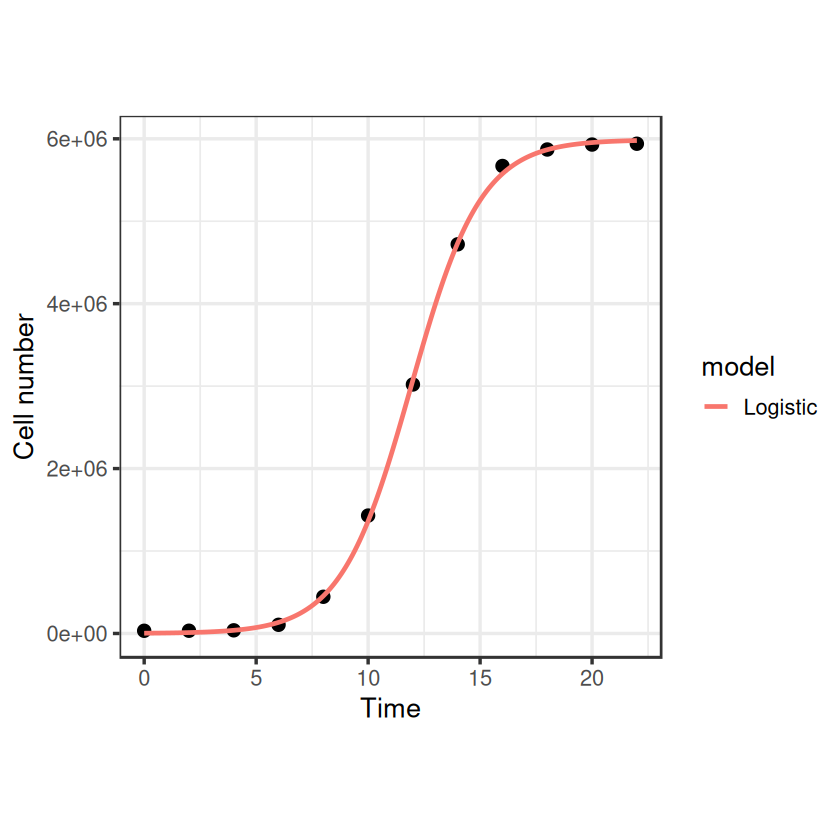
That looks nice, and it gives us an \(r_{max}\) estimate fairly close to what we had before: 0.64. Note that we’ve done this fitting to the original non transformed data, whilst the linear regressions earlier were on log transformed data. What would this function look like on a log-transformed axis?
head(data)
| Time | N | LogN | Log10N | |
|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | |
| 1 | 0 | 32499.88 | 10.38899 | 4.511882 |
| 2 | 2 | 33000.03 | 10.40426 | 4.518514 |
| 3 | 4 | 38000.11 | 10.54534 | 4.579785 |
| 4 | 6 | 104999.77 | 11.56171 | 5.021188 |
| 5 | 8 | 445000.04 | 13.00583 | 5.648360 |
| 6 | 10 | 1430000.05 | 14.17319 | 6.155336 |
data$LogN <- log(data$N)
data$Log10N <- log10(data$N)
ggplot(data, aes(x = Time, y = LogN)) +
geom_point(size = 3) +
geom_line(data = df1, aes(x = Time, y = log(N), col = model), size = 1) +
theme_bw(base_size = 16) +
theme(aspect.ratio=1)+
labs(x = "Time", y = "log(Cell number)")
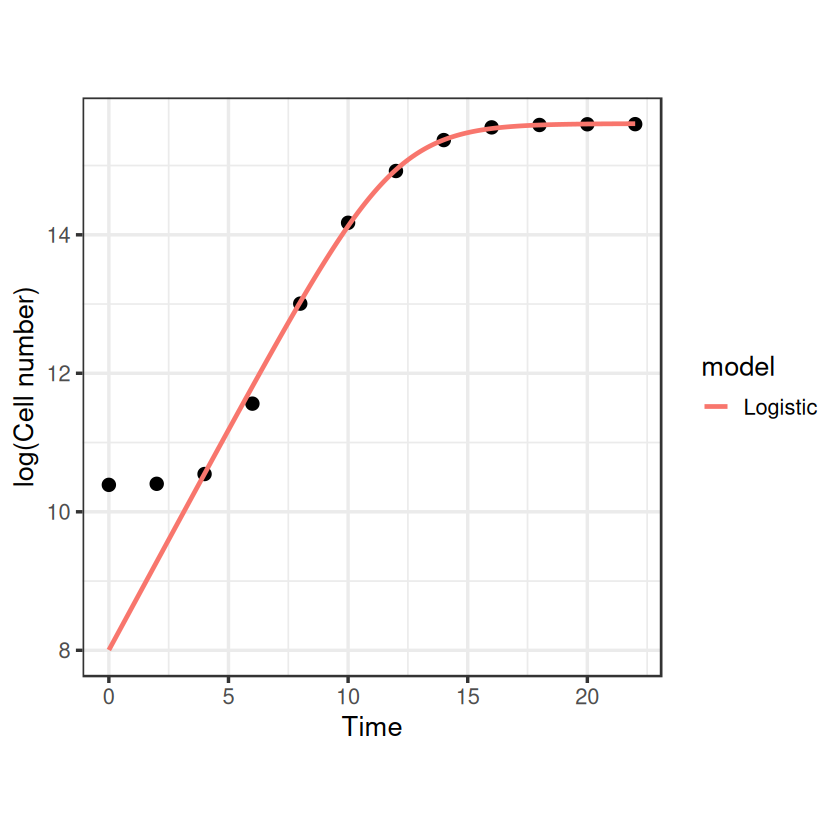
Aha, something weird happens at the lower end where our model diverges from the data. This is because the logistic model assumes that the population is growing from the start, however this is not true to reality for batch cultures of bacteria. When bacteria are sub-cultured into fresh media, they take some time to acclimate to their new surroundings, activating genes involved in nutrient uptake and metabolic processes before beginning exponential growth. This is called the lag phase and can be seen in our example data where exponential growth doesn’t properly begin until around the 4th hour. Various models have been devised to describe bacterial growth curves which include a lag phase before exponential growth begins. Here we will look at 3 - Gomertz, Baranyi and Buchanan. These all contain our three parameters from before (\(N_0\), \(N_{max}\) and \(r_{max}\)) and introduce a new one which describes the length of the lag period - (\(t_{lag}\)). The Buchanan model (or “three-phase logistic”; [Buchanan et al., 1997]) is very simplistic, based on the idea that you can get a decent estimate of bacterial growth from a simple straight line through the exponential phase on the logged data (similar to what we did earlier). It says that at \(N_0\) and \(N_{max}\), growth rate is zero, and between those points, growth rate is constant and \(r_{max}\) is simply the slope of the line. The Gompertz (using the log-transformed formulation of [Zwietering et al., 1990]) and Baranyi ([Baranyi et al., 1993]) models are mathematical functions describing the shape of the curve, where the maximum growth rate is estimated as the slope of the tangent to the inflection point of the curve. First, specify the model functions.
gompertz_model <- function(t, r_max, N_max, N_0, t_lag){ # Modified gompertz growth model (Zwietering 1990)
return(N_0 + (N_max - N_0) * exp(-exp(r_max * exp(1) * (t_lag - t)/((N_max - N_0) * log(10)) + 1)))
}
baranyi_model <- function(t, r_max, N_max, N_0, t_lag){ # Baranyi model (Baranyi 1993)
return(N_max + log10((-1+exp(r_max*t_lag) + exp(r_max*t))/(exp(r_max*t) - 1 + exp(r_max*t_lag) * 10^(N_max-N_0))))
}
buchanan_model <- function(t, r_max, N_max, N_0, t_lag){ # Buchanan model - three phase logistic (Buchanan 1997)
return(N_0 + (t >= t_lag) * (t <= (t_lag + (N_max - N_0) * log(10)/r_max)) * r_max * (t - t_lag)/log(10) + (t >= t_lag) * (t > (t_lag + (N_max - N_0) * log(10)/r_max)) * (N_max - N_0))
}
For added complication, note that these are written in log to the base 10, which means that we must use data transformed to log base 10, not the natural log as we did earlier. These could also be written in the natural log too, in which case you would natural log transform the data to fit them.
Now let’s generate some starting values for the nlls fitting, using some functions to derive these values from the actual data:
# Note that we're using Log10N now
N_0_start <- min(data$Log10N)
N_max_start <- max(data$Log10N)
t_lag_start <- data$Time[which.max(diff(diff(data$Log10N)))]
r_max_start <- max(diff(data$Log10N))/mean(diff(data$Time))
Now fit the models:
fit_gompertz <- nlsLM(Log10N ~ gompertz_model(t = Time, r_max, N_max, N_0, t_lag), data,
list(t_lag=t_lag_start, r_max=r_max_start, N_0 = N_0_start, N_max = N_max_start))
fit_baranyi <- nlsLM(Log10N ~ baranyi_model(t = Time, r_max, N_max, N_0, t_lag), data,
list(t_lag=t_lag_start, r_max=r_max_start, N_0 = N_0_start, N_max = N_max_start))
fit_buchanan <- nlsLM(Log10N ~ buchanan_model(t = Time, r_max, N_max, N_0, t_lag), data,
list(t_lag=t_lag_start, r_max=r_max_start, N_0 = N_0_start, N_max = N_max_start))
summary(fit_baranyi)
summary(fit_buchanan)
summary(fit_gompertz)
Formula: Log10N ~ baranyi_model(t = Time, r_max, N_max, N_0, t_lag)
Parameters:
Estimate Std. Error t value Pr(>|t|)
t_lag 4.75157 0.26603 17.86 9.89e-08 ***
r_max 0.78662 0.04063 19.36 5.26e-08 ***
N_0 4.47239 0.03389 131.98 1.21e-14 ***
N_max 6.75633 0.02187 308.90 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.0461 on 8 degrees of freedom
Number of iterations to convergence: 9
Achieved convergence tolerance: 1.49e-08
Formula: Log10N ~ buchanan_model(t = Time, r_max, N_max, N_0, t_lag)
Parameters:
Estimate Std. Error t value Pr(>|t|)
t_lag 3.69676 0.27026 13.68 7.86e-07 ***
r_max 0.56812 0.02251 25.24 6.51e-09 ***
N_0 4.51520 0.04372 103.27 8.63e-14 ***
N_max 6.74860 0.02765 244.05 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.06183 on 8 degrees of freedom
Number of iterations to convergence: 6
Achieved convergence tolerance: 1.49e-08
Formula: Log10N ~ gompertz_model(t = Time, r_max, N_max, N_0, t_lag)
Parameters:
Estimate Std. Error t value Pr(>|t|)
t_lag 4.518857 0.080943 55.83 1.18e-11 ***
r_max 0.755878 0.013951 54.18 1.49e-11 ***
N_0 4.511152 0.011236 401.48 < 2e-16 ***
N_max 6.799625 0.009583 709.57 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.01693 on 8 degrees of freedom
Number of iterations to convergence: 8
Achieved convergence tolerance: 1.49e-08
We’re in and around the same ballpark figure for r_max again, though Baranyi and Gompertz estimate higher than Buchanan. Note that \(N_0\) and \(N_{max}\) are estimated based on our log transformation, so the true carrying capacity in terms of cell number would be \(10^{N_{max}}\) for instance.
Plot them all together to see how the fits look.
timepoints <- seq(0, 22, 0.1)
baranyi_points <- baranyi_model(t = timepoints, r_max = coef(fit_baranyi)["r_max"], N_max = coef(fit_baranyi)["N_max"], N_0 = coef(fit_baranyi)["N_0"], t_lag = coef(fit_baranyi)["t_lag"])
buchanan_points <- buchanan_model(t = timepoints, r_max = coef(fit_buchanan)["r_max"], N_max = coef(fit_buchanan)["N_max"], N_0 = coef(fit_buchanan)["N_0"], t_lag = coef(fit_buchanan)["t_lag"])
gompertz_points <- gompertz_model(t = timepoints, r_max = coef(fit_gompertz)["r_max"], N_max = coef(fit_gompertz)["N_max"], N_0 = coef(fit_gompertz)["N_0"], t_lag = coef(fit_gompertz)["t_lag"])
df2 <- data.frame(timepoints, baranyi_points)
df2$model <- "Baranyi"
names(df2) <- c("Time", "Log10N", "model")
df3 <- data.frame(timepoints, buchanan_points)
df3$model <- "Buchanan"
names(df3) <- c("Time", "Log10N", "model")
df4 <- data.frame(timepoints, gompertz_points)
df4$model <- "Gompertz"
names(df4) <- c("Time", "Log10N", "model")
model_frame <- rbind(df2, df3, df4)
ggplot(data, aes(x = Time, y = Log10N)) +
geom_point(size = 3) +
geom_line(data = model_frame, aes(x = Time, y = Log10N, col = model), size = 1) +
theme_bw(base_size = 16) +
theme(aspect.ratio=1) +
labs(x = "Time", y = "log10(Cell number)")
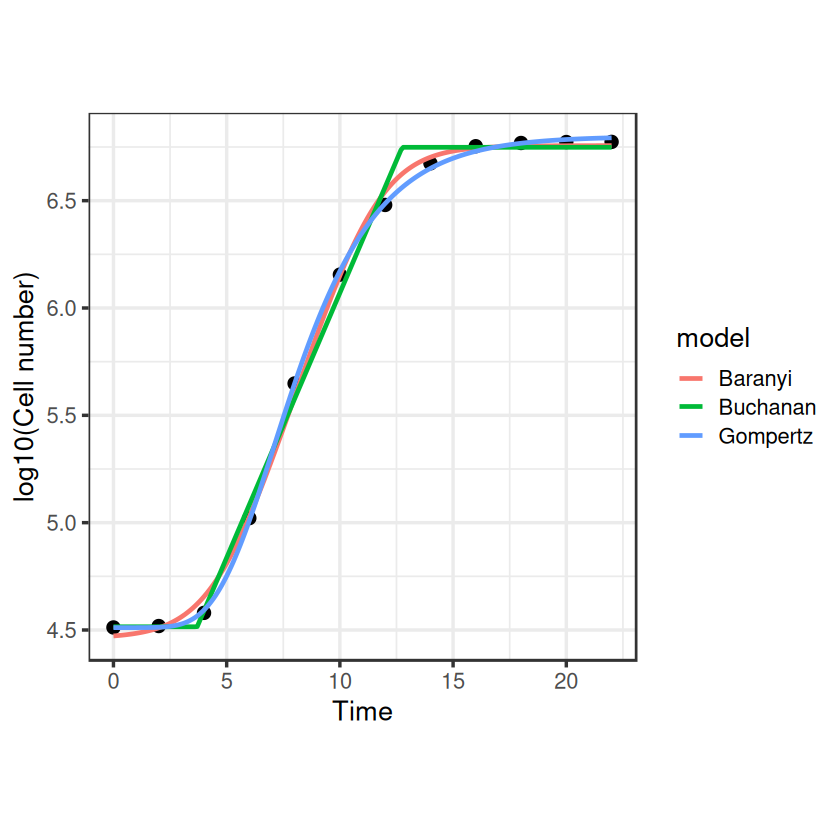
So they look like they do a pretty nice job of fitting the full exponential growth curve, but we should use some model selection to choose the best one for our dataset.
AIC(fit_gompertz, fit_baranyi, fit_buchanan)
| df | AIC | |
|---|---|---|
| <dbl> | <dbl> | |
| fit_gompertz | 5 | -58.69545 |
| fit_baranyi | 5 | -34.65831 |
| fit_buchanan | 5 | -27.61096 |
So for these data, Gompertz seems to be the best fit (lowest AIC).
We could also check the confidence intervals on the parameters.
confint(fit_gompertz)
Waiting for profiling to be done...
| 2.5% | 97.5% | |
|---|---|---|
| t_lag | 4.3332398 | 4.6991080 |
| r_max | 0.7253675 | 0.7882898 |
| N_0 | 4.4851698 | 4.5367871 |
| N_max | 6.7779349 | 6.8217828 |
So our \(r_{max}\) estimate from the best fitting model (Gompertz) is 0.76 with CIs 0.73-0.79. Job done.
Alternative starting parameters#
But this is just for our single curve, fitting these models to a whole database of different growth rate measurements can pose more problems. In particular, these nls models can be quite fussy about their paramater starting values and fail to converge if these are too far from reality. We implemented some functions to estimate the starting parameters, but these can fail to give decent estimations if there are some oddities in the data. One nice way of getting around this is using the nls.multstart package (from Dan Padfield again - padpadpadpad/nls.multstart) which allows you to specify a general range of starting parameters which it iterates across. It attempts to fit with each set of starting parameters and then chooses the best model fit based on AIC scores. Lets use this on our Gompertz fitting code from before.
# fit gompertz model with multiple starting parameters
fit_gompertz_multi <- nls_multstart(Log10N ~ gompertz_model(t = Time, r_max, N_max, N_0, t_lag),
data = data,
start_lower = c(t_lag=0, r_max=0, N_0 = 0, N_max = 0),
start_upper = c(t_lag=20, r_max=10, N_0 = 6, N_max = 10),
lower = c(t_lag=0, r_max=0, N_0 = 0, N_max = 1),
iter = 500,
supp_errors = "Y")
fit_gompertz_multi
Nonlinear regression model
model: Log10N ~ gompertz_model(t = Time, r_max, N_max, N_0, t_lag)
data: data
r_max N_max N_0 t_lag
0.7559 6.7996 4.5112 4.5189
residual sum-of-squares: 0.002294
Number of iterations to convergence: 16
Achieved convergence tolerance: 1.49e-08
Good, that’s bang on what we got before. So if you see lots of “singular gradient matrix at initial parameter estimates” error messages when trying to do nls fitting, starting parameters are likely a problem and this package offers a way to easily get around that.
Doubling Time#
Just a side-note that sometimes doubling times (or generation times) are reported in the literature rather than growth rates, but it is simple to work back the growth rate from the doubling time. Similar to the exponential growth function earlier, the formula for the doubling of a population can be given by:
\( N(t) = N_0 \cdot 2^{n} , \)
where \(n\) is the number of generations over the time period. The doubling time (the period of time for a population to double in size, \(T_d\)) is given by \(T_d = t/n\), therefore:
\( N(t) = N_0 \cdot 2^{t/T_d} . \)
Taking the log of both sides we get:
\( \log(N(t)) = \log(N_0) + \frac{t}{T_d} \cdot \log(2) . \)
After some re-arrangement, we can find that:
\( T_d \frac{\log(N(t)) - \log(N_0)}{t} = \log(2). \)
If we remember from earlier than the specific growth rate, \(r_{max}\) (or sometimes, \(\mu\)) can be given by:
\( r_{max} = \frac{\log(N(t)) - \log(N_0)}{t} , \)
then we can substitute this into our equation and with a little more rearranging find:
\( T_d = \frac{\log(2)}{r_{max}} . \)
So it is simple to work back the growth rate from the doubling time, or vice-versa.
references#
Zweitering, Jongenburger, rombouts and Van ‘T riet, “Modelling of the bacterial growth curve”, Applied and Environmental Microbiology, 1990.
Buchanan, Whiting and Damert, “When is simple good enough: a comparison of the Gompertz, Baranyi, and three-phase linear models for fitting bacterial growth curves”, Food Microbiology, 1997.
Baranyi, roberts and McClure, “A non-autonomous differential equation to model bacterial growth”, Food Microbiology, 1993.